Implementing a Security Labeling Service for Data Segmentation
- 9 minsThe security labeling service (SLS) is a software service that determines the security labels for a data item or collection of data items, for example, a FHIR resource, a FHIR bundle, or a CDA document.
Labels are assigned based on applicable labeling rules; these rules may originate from various sources:
- clinical knowledge, for example, a rule that specifies which clinical codes are indicative of a specific class of sensitive information,
- security and privacy policies, for example, “any record related to substance use treatment should be labelled as restricted”, or
- business and workflow rules, for example, “any information received from a facility known to provide substance use treatment, should be labeled accordingly”.
In cases where the data contains unstructured text, natural language processing tools and services are sometimes necessary to infer clinical concepts implied by the unstructured text, in order to determine the security labels.
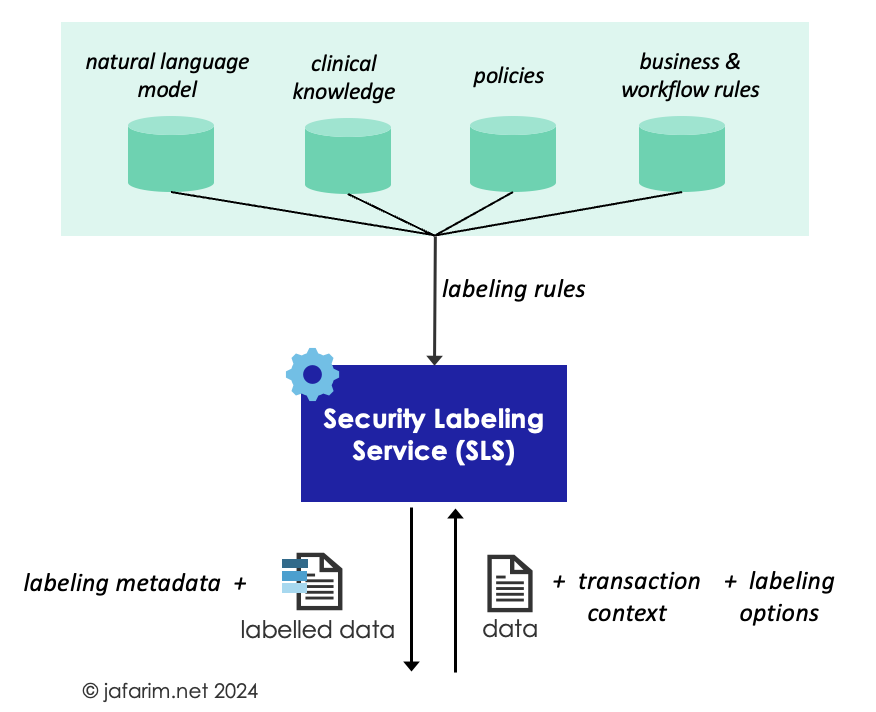 Figure 1. Security Labeling Service (SLS).
Figure 1. Security Labeling Service (SLS).
Implementing SLS requires some major components and design decisions which I discuss in this post. This expands on the brief Implementation Notes provided in the FHIR Data Segmentation for Privacy (DS4P) Implementation Guide.
The first step is to design and encode the labeling rules in a computable form so that they can be retrieved, parsed, and enacted by the SLS as applicable. For this, a rules language is needed, and if the rules are managed separately from the SLS, an API to interact with the rules is also required.
Labeling rules are designed by various stakeholders including policy experts and clinicians, so, usually a user friendly rules authoring and management interface is also desired.
Currently, there are no standard specification for the format of such rules or how they can be stored and retrieved. I wrote a brief proposal on using FHIR resources for recording SLS rules but that is admittedly too complex and perhaps an overkill at least for the current state of SLS adoption and implementation.
To record the labels on data, we need a standard mechanism consistent with the format of the data item to enable tagging the data with a label. For FHIR resources, meta.security attribute defined in the FHIR core can be used for this purpose. For more granular sub-resource labeling in FHIR, the inline labeling mechansim is defined by the FHIR Data Segmentation for Privacy (DS4P) Implementation Guide.
For CDA documents, the Data Segmentation for Privacy (DS4P) Implementation Guide for CDA defines how to record labels at the document, section, and entry levels.
For HL7v2 messages, guidance is provided in Version 2.9 for Patient Administration Access Control Restriction Value Segment (ARV), the Control description of the Batch Header Segment (BHS), the File Header Segment (FHS), and the Message Header Segment (MSH).
The standard formats for security labels define where in the data object the label can be recorded but in order to record a label, we also need to have standard codes for representing the label itself (e.g., substance use treatment or reproductive health). These codes are defined and maintained as part of the HL7 terminology and a summary of all the value sets for different types of security labels is included in the FHIR DS4P Implementation Guide.
These value sets need to be maintained and updated on a regular basis to accommodate new classes of sensitive data identified in emerging laws and regulations. There is also a need for standard specifications to provide unifying guidelines on the precise codes that should be used for each corresponding legislation and policy in the US realm in order to ensure that different SLS implementations use these codes consistently.
Finally, a standard API is needed to specify how to invoke the SLS, how to provide it with the data to be labeled, and the format in which the response should be returned. There is currently no standard specification for such an SLS API.
Aside from the data to be labeled, the request should optionally allow the caller to specify what type of labels it is expecting to be assigned (e.g., only sensitivity labels). Moreover, the caller also needs a mechanism to provide other contextual information such as the purpose of use or the identity of the data requester. This context is important for determining labels (such as handling instructions) that depend on such metadata.
Note that when processing granular data, such as FHIR resources, a sophisticated labeling decision may also rely on related data items not directly present in the request. This means the SLS may need to access some related data (e.g., the related FHIR Encounter) to establish the context for the data items in question and incorporate that in the labeling decision. One strategy is to provide the SLS with direct access to the data source. This is easier when the SLS is within the same domain but if the SLS is a third-party service, providing such access can be complex both from the policy and liability perspective, as well as technical perspective and authorization management. An alternative is to allow the SLS to ask for additional data items directly from the caller. These issues resemble those regarding data access in Clinical Decision Support (CDS) Hooks, so, that may be a good starter candidate for an SLS API.
The response may optionally include metadata about the label, such as the rationale for the labeling decision or the elements within the data object that matched a labeling rule. Such metadata may also be recorded on the data object alongside the labels when the specification is available. For example, the FHIR DS4P Implementation Guide defines extensions for recording the policy basis for the labeling and the identity of the labeler.
Finally, policy guidelines and agreements should be established to govern how the recipient of labeled data should process it and the measures it should take once it receives data bearing a particular label.
Operational Models
To integrate labeling into a system, at some point in the systems workflows, the SLS needs to be invoked and provided with the data to be labeled. There are two main patterns for incorporating the SLS into the system workflows.
In the batch model, data is submitted to the SLS by a batch processor that acts as an orchestrator for labeling by submitting the data (based on various criteria and priority heuristics) to the SLS, and subsequently persisting the labeled data back in the data source. The batch processor works offline, outside of the context of live transactions.
The labeling may be triggered based on events, such as a bulk import of new data or an update event that changes the content of a data item. It may also be based on a schedule to submit existing data to the SLS to be labeled. Ultimately, a priority queue may be used to trace the data awaiting to be labeled and to allow prioritizing certain labeling jobs over others.
Since the batch processor operates offline, it is not bound by the latency requirements of a transaction, and therefore can request labeling involving more heavy computations such as processing unstructured text.
But for the same reason, since it does not have access to the transaction context, it cannot call for assigning labels based on rules that depend on the context of a transaction such as the identity of a recipient or purpose of use. Furthermore, since data is labeled in advance and ahead of a transaction, it may have to be re-labeled if the content of the data item is updated, or in case labeling rules change.
Another disadvantage of batch labeling is the need for persisting the labels which may not be supported by the data source in case access to the data source is read-only, or if the underlying technology does not support persisting labels for other reasons.
Finally, if engineered poorly, batch labeling may waste resources by labeling a large volume of legacy data that may never be requested or used. This is particularly important for large data sources where only a fraction of the data may ever be accessed or requested to be exchanged.
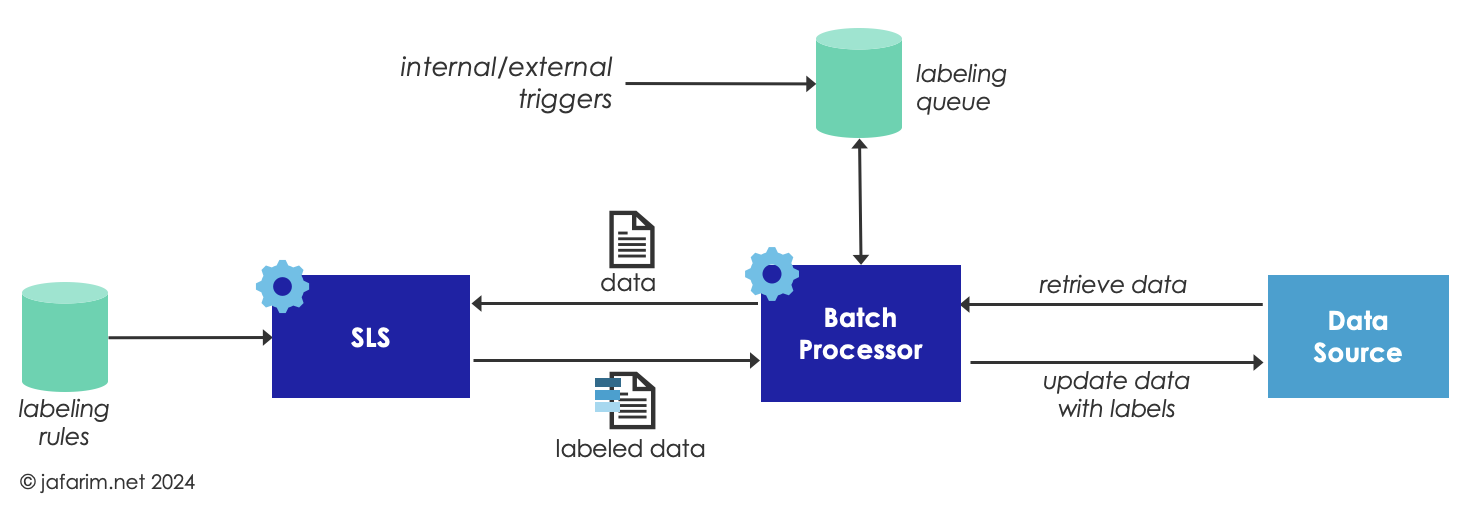 Figure 2. Batch Labeling.
Figure 2. Batch Labeling.
An alternative approach is to label the data on-the-fly and within the context of a transaction. In this model, the SLS is invoked by the authorization service, after a request for data is received, and before the data is returned to the requester. The requested data is submitted to the SLS together with the full context of the transaction. Subsequently, based on the assigned labels and other policies (including patient consent), the authorization service can decide whether to decline the request entirely or fulfill the request by sending only a subset of the data (i.e., after redacting what is not authorized to share), or share the labeled data and allow the recipient to appropriately process it based on the labels.
On-the-fly labeling has the advantage of having access to the full context of the transaction which enables assigning labels based on rules that depend on that context. For example, a labeling rule such as “all sensitive data sent to a recipient in a different state should be labeled with delete after use” hinges on knowing the geographical location of the requesting party.
The other advantage of this approach is that the labeling is always based on the most recent version of the data and labeling rules, so, re-labeling is not needed. For the same reason, it does not require the underlying data source to support persisting labels which enables further decoupling from the details of the data source implementation. This comes with the downside of having to repeat some of the labeling computations when data is requested again, since the assigned labels are lost once the transaction is completed.
Another disadvantage of on-the-fly labeling is that it is bound by the latency requirements for the transaction and if the transaction is synchronous, heavy computations such as processing unstructured text may not be feasible.
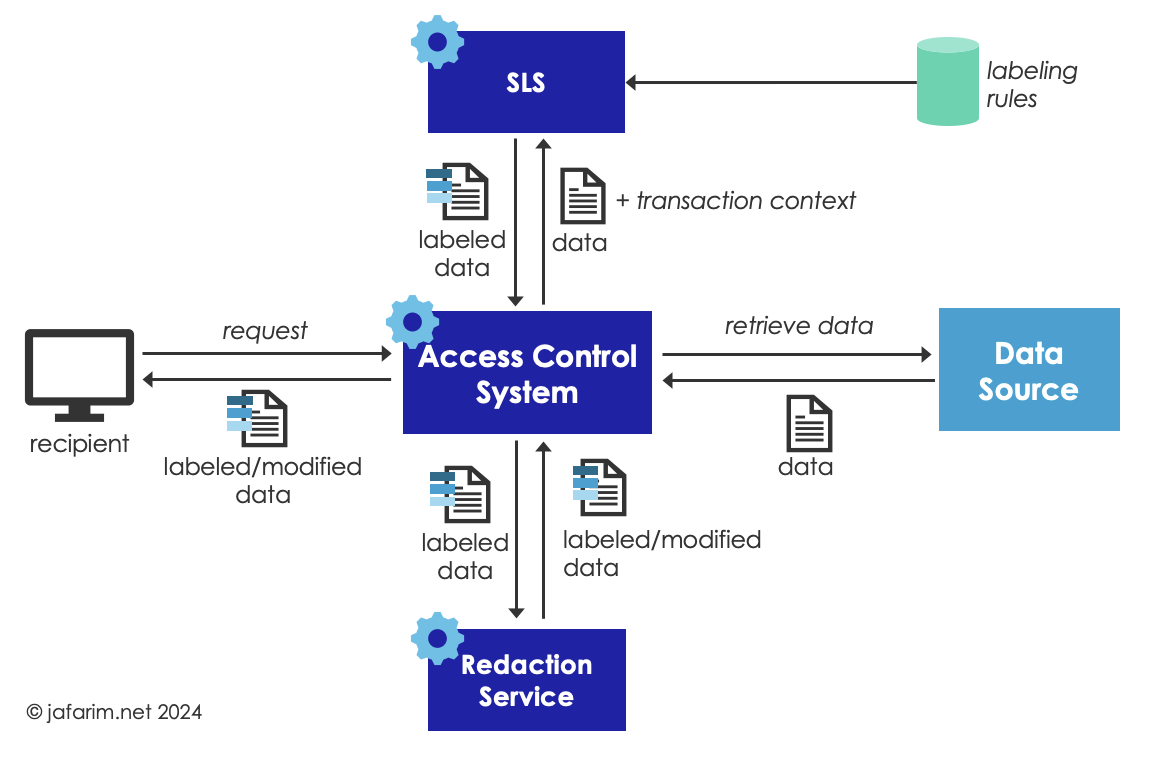 Figure 3. On-the-Fly Labeling.
Figure 3. On-the-Fly Labeling.
Ultimately, a tailored solution to implementing the SLS usually requires a hybrid approach to balance the advantages and disadvantages of each model. For example, some of the assigned labels during an on-the-fly labeling can be persisted or cached to avoid re-labeling for frequently-requested data. Or, a batch labeler can be used to do some labeling (e.g., sensitivity labels that do not depend on the transaction context) while on-the-fly labeling may be used to add additional labels at the time of the transaction.